逃离豆瓣 - 使用Org-mode管理我的书影音

文章目录
【注意】最后更新于 May 30, 2022,文中内容可能已过时,请谨慎使用。
小贴士
我的豆瓣书影音替代方案基于Org-mode,如果对此感兴趣的话可以阅读我的另一篇博客《继续吹一波Org-mode》了解Org-mode以及更多用法。最近豆瓣开始搞激烈的实名认证,而不愿献祭隐私的我,也只能和豆瓣说再见了。豆瓣十几年的情谊化为乌有,我也无法相信其他书影音数据库能够天长地久。另一方面,IMDB,Letterbox,TMDB,Goodreads这类美国数据库对于动漫和国产书还有水土不服的问题,我曾经暂别豆瓣,用过挺长一段时间的IMDB+Letterbox,却还是回归豆瓣后觉得顺手。查了一下,似乎没有什么自架豆瓣替代品的开源软件,大家常用的方案也是我不太喜欢的Notion(我在继续吹一波Org-mode里曾经详述过),于是趁着小长假,我便将豆瓣转移到了Org-mode。
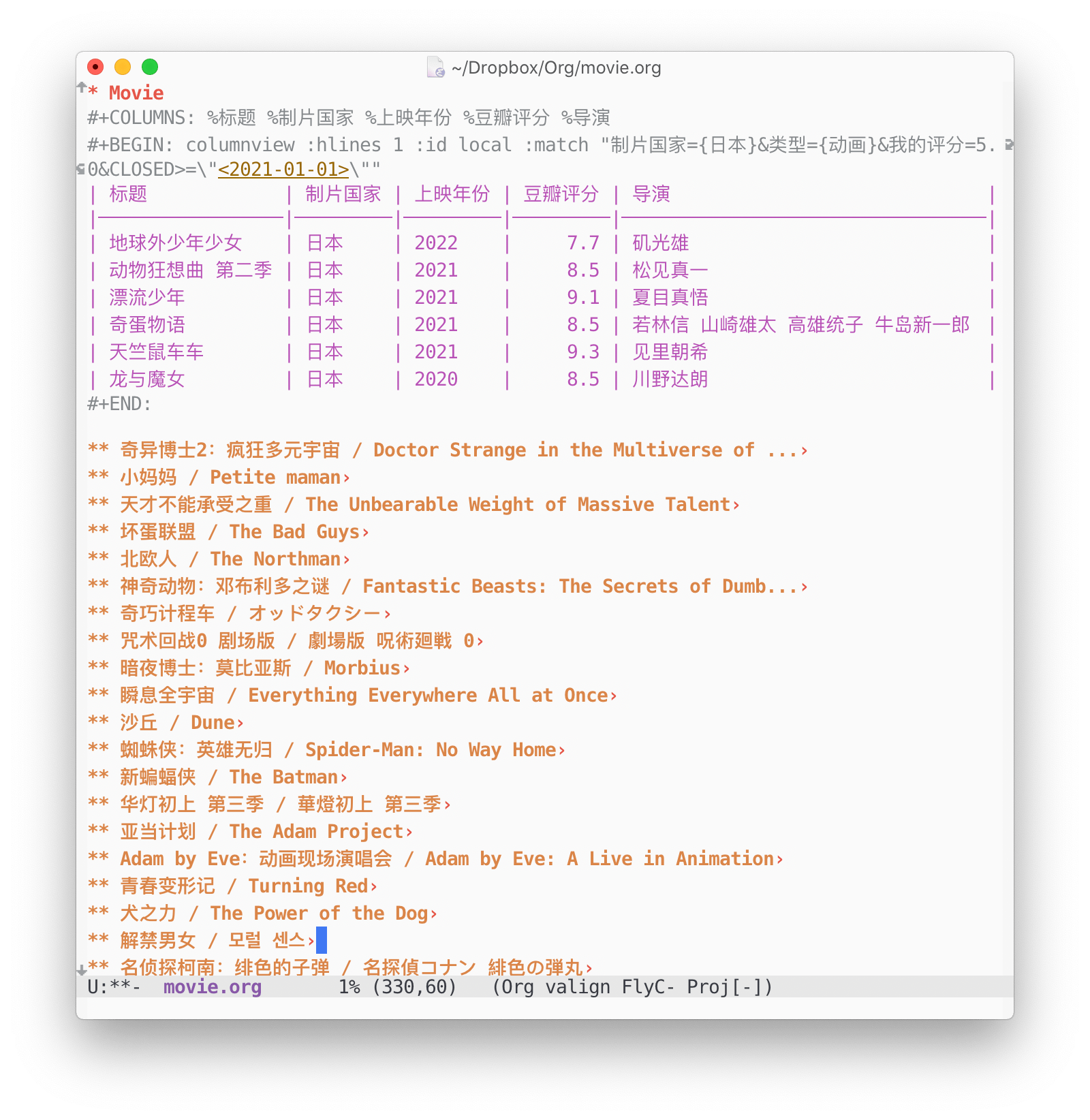
Figure 1: 最终效果长这样
导出我的书影音
因为懒得造轮子,我便找了几个导出方案。一个是基于Chrome扩展的豆坟,另一个则是这位博主写的使用Greasemonkey的脚本。这两个都是基于我看,我读,我听这些页面导出的,好处是快捷且不容易被当成机器人被封禁,坏处是没有imdb和isbn等条目信息,无法获得更详尽的资料。我也尝试了爬虫,但是没几页ip就被封了。我最大的意见是这两个导出方案缺少电影,电视剧,动漫,综艺的分类。
转换为org file
我将这两个方案得到的文件进行交叉比对后,就可以转换为org文件了。这一步我用了pandas,先生成一个和org properties格式对应的列(通过\n来换行),然后再将该列输出为后缀为org的csv,最后使用通配符将需要双引号删除即可。我的org文件大概长这样:
** 小妈妈 / Petite maman <-这里是脚本得到的标题
CLOSED: [2022-05-09 11:37:52] <-这里是豆坟导出的创建时间
:PROPERTIES:
:标题: 小妈妈
:原名: Petite maman
:上映年份: 2021
:上映日期: 2021-03-03
:制片国家: 法国 <-注意脚本得到的制片国家是错误的,使用豆坟即可
:类型: 剧情 奇幻
:导演: 瑟琳·席安玛
:主演: 约瑟芬·桑兹 加布里埃尔·桑兹
:豆瓣链接: https://movie.douban.com/subject/35225859/
:豆瓣评分: 7.9
:我的评分: 5.0
:END:
快速查询与管理
使用Org-mode管理的最大优势就是作为纯文本,却可以使用sparse tree来筛选特定条目或者通过column view方便地将内容转为表格进行查询和函数运算。
我使用 C-c / 开启 sparse tree后,我可以方便地通过 p 筛选特定 property,也可以通过 m 去筛选特定 match pattern。比如我想筛选日本动画,即可打 C-c / m 后在mini buffer输入 制片国家={日本}&类型={动画} ,这个org文件中所有日本动画便会高亮,而不满足此条件的条目则会暂时隐藏。
我也可以使用 C-c C-x C-c 开启 column view,方便地进行各种操作。默认的column view是和项目完成度相关的,在书影音的管理上用处不大。所以我需要先定义 #+COLUMNS 或是 COLUMNS property,然后开启 column view 后,便会显示相应的列。
#+COLUMNS: %标题 %制片国家 %上映年份 %豆瓣评分 %导演
Column view 其实就是改变了 buffer 的显示方式,但是有的时候我想将筛选的结果分享。这时候就可以和Orgmode的动态模块 dynamic blocks 相结合了。比如说我想找到所有2021年后我看完之后非常喜欢而打了5分的日本动漫,就可以在文件中写以下的动态模块。
#+BEGIN: columnview :hlines 1 :id local :match "制片国家={日本}&类型={动画}&我的评分=5.0&CLOSED>=\"<2021-01-01>\""
#+END:
然后,在动态模块上 C-c C-c ,Org-mode就会自动帮我找到所有满足条件的条目,并以纯文本的形式填充这个动态模块,非常方便。不过column view相比sparse tree,在速度上明显要慢很多。相比sparse tree的即时性,column view在我八百多条记录里要找大概两三秒才能生成最后的结果。
#+BEGIN: columnview :hlines 1 :id local :match "制片国家={日本}&类型={动画}&我的评分=5.0&CLOSED>=\"<2021-01-01>\""
| 标题 | 制片国家 | 上映年份 | 豆瓣评分 | 导演 |
|-------------------+---------+------+--------------+-------------------------------------|
| 地球外少年少女 | 日本 | 2022 | 7.7 | 矶光雄 |
| 动物狂想曲 第二季 | 日本 | 2021 | 8.5 | 松见真一 |
| 漂流少年 | 日本 | 2021 | 9.1 | 夏目真悟 |
| 奇蛋物语 | 日本 | 2021 | 8.5 | 若林信 山崎雄太 高雄统子 牛岛新一郎 |
| 天竺鼠车车 | 日本 | 2021 | 9.3 | 见里朝希 |
| 龙与魔女 | 日本 | 2020 | 8.5 | 川野达朗 |
#+END:
添加新条目
最后一个问题就是如何更新条目了。由于是纯文本,我可以直接手打来添加条目,这样也可以增加一些豆瓣缺少的信息,比如系列构成,出品公司等。我也打算写一个简单的脚本来从豆瓣,IMDB,Bangumi上自动获取信息加入org文件中。
文章作者
上次更新 2022-05-30